On February 5th, OpenAI and Anthropic dropped competing flagship coding models within minutes of each other. The question everyone asked next misses what actually matters: which one is "better"?
GPT-5.3-Codex and Claude Opus 4.6 represent a fundamental shift in how AI labs compete. We've moved past the benchmark wars into something messier and more interesting: the usability wars. Raw technical capability no longer determines which tool wins. What matters is which one actually ships code you can trust.
Early testing reveals a split that cuts to the heart of how we build software: Codex is faster and technically stronger at pure coding. Opus is slower but more reliable at catching its own mistakes. The difference isn't about power. It's about what kind of power you actually need.
The Speed Trap
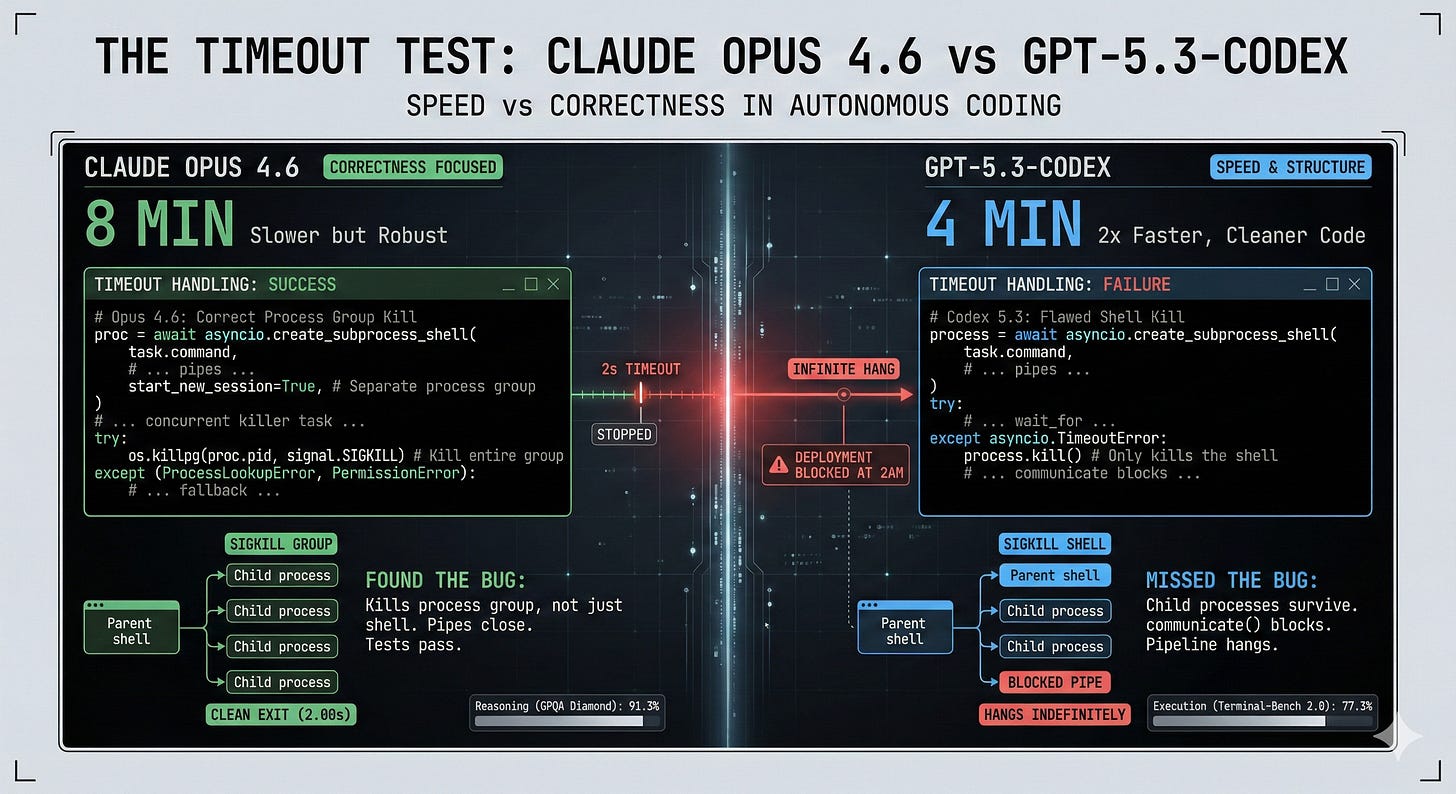
Tyler Folkman ran both models on the same task: build a production-ready Hacker News clone. The results tell you everything about this debate.
Codex finished in 4 minutes. Opus took 8 minutes. Codex generated clean, senior-level code that Folkman described as coming from "an engineer who cares about craft." It looked impressive. It shipped fast.
It also shipped a bug.
Opus took twice as long. But it wrote 28 tests to Codex's 5. And crucially, one of those tests failed. Opus caught its own bug during validation. Codex never knew it had a problem.
This isn't about which model is "smarter." Both are incredibly capable. Codex scores 56.8% on SWE Bench Pro, while Opus leads on Terminal-Bench 2.0. The benchmarks are close enough that they're basically noise.
The difference is what happens after the impressive demo. Does the code actually work? Did the model understand what "production-ready" means? Can you ship it without reading every line?
What You're Actually Choosing
The builder community is splitting into predictable camps based on what they value most.
Choose Codex if:
- You know exactly what you want and can spot problems quickly
- Speed matters more than self-validation
- You're comfortable babysitting the model with detailed descriptions
- You need raw technical capability on complex algorithmic problems
One developer noted that Codex "feels much more Claude-like" than previous OpenAI models, with faster feedback and broader task capability. It's genuinely impressive at the "98% of requirements" that make up most development work.
But that remaining 2% matters. Multiple testers report that Codex can "skip files, put stuff in weird places" when handling context-heavy fixes. It optimizes for the happy path. When things get messy, it keeps moving fast instead of slowing down to think.
Choose Opus if:
- You need the model to catch its own mistakes
- You're building production systems where bugs are expensive
- You value thorough testing over fast iteration
- You want a model that understands context without constant hand-holding
Opus 4.6 ships with features designed for reliability: 200K token context windows (1M in beta), 128K output tokens, adaptive thinking, and configurable effort levels. It scores 76% on long-context retrieval tasks. More importantly, it seems to understand when to slow down and validate its own work.
The tradeoff is real. Opus takes longer. For repetitive CRUD operations, that slowness feels unnecessary. But for anything involving business logic, edge cases, or complex state management, the extra time buys you something valuable: trust.
The Post-Benchmark Era
This simultaneous release signals something bigger than a feature war. We're watching AI labs figure out what actually matters beyond impressive demos.
Both models are available on $20/month consumer plans. Both handle agentic workflows, multi-step debugging, and codebase-wide operations. The technical specs are close enough that choosing based on raw power is pointless.
What matters is fit. Do you need a technically brilliant model that occasionally ships bugs, or a slightly slower one that catches them? Do you want to review every output, or trust the model to validate itself?
The answer depends entirely on what you're building and how you work. If you're prototyping fast and can catch issues quickly, Codex's ~25% speed improvement adds up. If you're building production systems where downtime costs real money, Opus's thoroughness is worth the wait.
What This Means for Builders
The Codex vs Opus debate reveals a maturation in how we think about AI coding tools. The question isn't "which model is better?" It's "better for what?"
This mirrors every other tool choice developers make. Fast compilers vs safe type systems. Move-fast frameworks vs battle-tested libraries. Developer experience vs performance. There's no universal answer because there's no universal context.
The real lesson: stop treating AI models like they're competing for some objective crown. They're optimizing for different things because different things matter in different situations.
Both models will get faster and more reliable. The gap will narrow. But the fundamental tension between speed and validation, impressive output and production-ready code, won't disappear. It's baked into what we're asking these tools to do.
Choose based on your actual workflow, not someone else's benchmark. Run your own tests on your own problems. And maybe stop asking which one is "better" and start asking which one actually helps you ship.